












- 글로벌 시장에서도 독보적 1위
읽고 쓰기도, 텍스트 추출도,
렌더링도 가장 빠른 속도를 자랑합니다.
-
PDF 문서 읽고 다시 쓰기 (복사) 소요시간
3.05
(시간) -
텍스트 전문 추출 및
파일 저장 소요시간8.01
(시간) -
동일한 해상도로
문서 렌더링 시 소요시간367.04
(시간)
* 7,031 페이지 기준
LLM·RAG 서비스 구현부터 AI 데이터베이스 구축까지 문서 데이터가 필요한 모든 분야에 활용할 수 있는 파이썬 라이브러리입니다.
인공지능 및 빅데이터 구축, 업무 자동화, 이미지 렌더링 등
다양한 문서 작업을 파이썬 환경에서 빠르고 정확하고 자유롭게 구현해 보세요.
인공지능 및 빅데이터 구축, 업무 자동화, 이미지 렌더링 등
다양한 문서 작업을 파이썬 환경에서 빠르고 정확하고 자유롭게 구현해 보세요.
-
독보적인 데이터 추출 속도를
직접 확인하세요. -
데모 페이지에서 직접 PDF 추출을
체험해 보실 수 있습니다.
★ 주기능
-
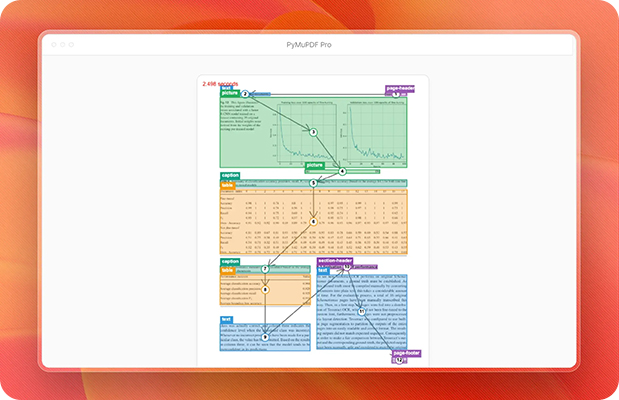
문서 속 핵심 정보를
빠르고 정확하게 추출하세요. -
복잡한 문서 구조를 분석하여 제목부터 본문, 캡션까지
눈으로 읽는 순서와 동일하게 텍스트를 추출합니다.


★ 특장점
- 문서 구조 그대로, 정확한 인식
-
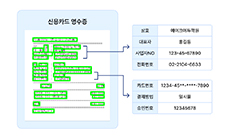
PDF 문서 내 표 영역을 인식하여
표 구조 그대로 변형 없이 추출합니다.
★ 편의기능
- 별도 설치 없이 더 가볍고, 더 빠르고, 더 유연하게
-
어플리케이션 코드 내에 직접 삽입하는 라이브러리로
문서 처리를 위한 기능 전반을 제공합니다.
-
복잡한 구조 문서 데이터도 정확하게복잡한 구조 문서 데이터도 정확하게

이미지, 표, 리스트, 문서 내 좌표정보까지
-
CPU, GPU, OS 상관 없이 사용 가능CPU, GPU, OS 상관 없이 사용 가능

파이썬 설치가 가능한 경우 자유롭게 사용하세요
-
LLM 및 오피스 문서 특화 기능 지원LLM 및 오피스 문서 특화 기능 지원

LlamaIndex Reader, 메타데이터를 포함한 Chunk생성도 가능합니다
ePapyrus ePapyrus ePapyrus
- Applications
-
데이터 인식 및 활용, 문서 관리 등
폭 넓게 활용할 수 있습니다
-

LLM ㆍRAG
LLM, RAG 학습 효율 향상 및
문서 기반 대화형 서비스 개발을 합니다. -

업무 자동화
문서 내 필요한 정보만 추출,
빠르고 정확한 업무 자동화 실현합니다. -

데이터 베이스 구축
비정형 문서를 문서 구조 그대로
데이터 추출하여 활용도 향상